My stated goal in this series of posts is to create a working containerized
Pulp service running in a
Kubernetes cluster. After, what is it, 5 posts, I'm finally actually ready to do something with pulp itself.
The Pulp service proper is made up of a single
Celery beat process, a single resource manager process, and some number of pulp worker processes. These together do the work of Pulp, mirroring and managing the content that is Pulp's payload. The service also requires at least one Apache HTTP server to deliver the payload but that comes later.
All of the Pulp processes are actually built on Celery. They all require the the same set of packages and much of the same configuration information. They all need use the
MongoDB and the
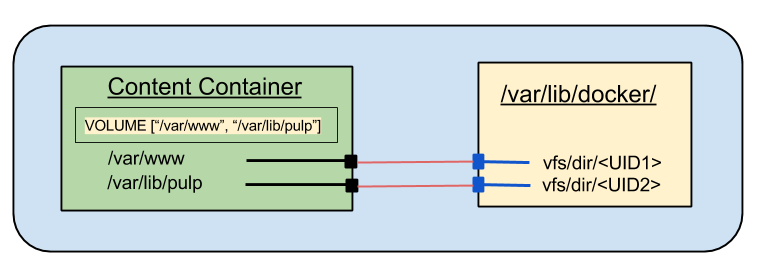
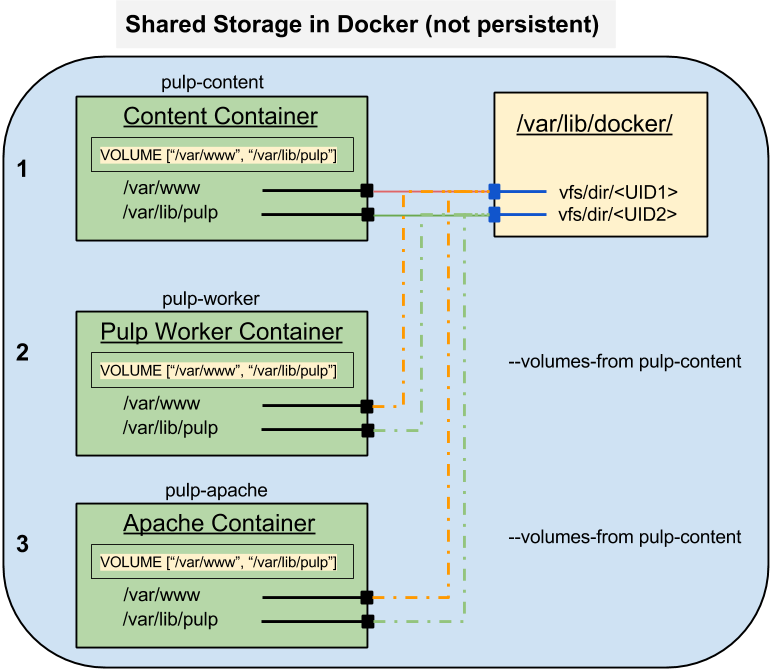
QPID services. The worker processes all need access to some shared storage, but the beat and resource manager do not.
To build the
Docker images for these different containers, rather than duplicating the common parts, the best practice is to put those parts into a
base image and then add one last layer to create each of the variations.
In this post I'll demonstrate creating a shared base image for Pulp services and then I'll create the first image that will consume the base to create the Pulp beat service.
The real trick is to figure out what the common parts are. Some are easy though so I'll start there.
Creating a Base Image
For those of you who are coders, a base image is a little like an abstract class. It defines some important characteristics that are meant to be re-used, but it leaves others to be resolved later. The Docker community already provides a set of base images like the Fedora:20 image which have been hand-crafted to provide a minimal OS. Docker makes it easy to use the same mechanism for building our own images.
The list below enumerates the things that all of the Pulp service images will share. When I create the final images I'll add the final tweaks. Some of these will essentially be stubs to be used later.
- Pulp Repo file
Pulp is not yet standard in the RHEL, CentOS or Fedora distributions
- Pulp Server software
- Communications Software (MongoDB and QPID client libraries)
- Configuration tools: Augeas
There is also some configuration scripting that will be required by all the pulp service containers:
- A script to apply the customization/configuration for the execution environment
- A test script to ensure that the database is available before starting the celery services
- A test script to ensure that the message service is available
Given that start, here's what I get for the Dockerfile
Lines 1 and 2 should be familiar already. There are no new directives here but a couple of things need explaining.
- Line 1: The base image
- Line 2: Contact information
- Line 4: A usage comment
Pulp uses syslog. For a process inside a container to write to syslog you either have to have a syslogd running or you have to have write access to the host's /dev/log file. I'll show this gets done when
I create a real app image from this base and run it.
- Line 6: Create a yum repo for the Pulp package content.
You can add files using a URL for the source.
- Lines 9-12: Install the Pulp packages, QPID client software and Augeas to help configuration.
- Lines 15-17: COMMENTED: Install and connect the Docker content plugin
This is commented out at the moment. It hasn't been packaged yet and there are some issues with dependency resolution. I left it here to remind me to put it back when the problems are resolved.
- Line 20: Add an Augeas lens definition to manage the Pulp server.conf file
Augeas is suitet for managing config values, when a lens exists. More detail below
- Line 23: Add a script to execute the configuration
This will be used by the derived images, but it works the same for all of them
- Line 27: Add a script which can test for access to the MongoDB
Pulp will just blindly try to connect, but will just hang if the DB is unavailable. This script allows me to decide to wait or quit if the database isn't ready. If I quit, Kubernetes will re-spawn a new container to try again.
The Pulp Repo
The Pulp server software is not yet in the standard Fedora or EPEL repositories. The packages are available from the contributed repositories on the Fedora project. The repo file is also there, accessible through a URL.
The docker
RUN directive can take a URL as well as a local relative file path.
Line 4 pulls the Pulp repo file down and places it so that it can be used in the next step.
Pulp Packages (dependencies and tools)
The Pulp software is easiest installed as a YUM group. I use a Dockerfile RUN directive to install the Pulp packages into the base image. This will install most of the packages needed for the service, but there are a couple of additional packages that aren't part of the package group.
Pulp can serve different types of repository mirrors. These are controlled by content plugins. I add the RPM plugin, python-pulp-rpm-common. I also add a couple of Python QPID libraries. However you can't run both
groupinstall and the normal package
install command in the same invocation so the additional Python QPID libaries are installed in a second command.
I also want to install
Augeas. This is a tool that enables configuration editing using a structured API or CLI command.
Augeas Lens for Pulp INI files
Augeas is an attempt to wrangle the flat file databases that make up the foundation of most *NIX application configuration. It offers a way to access individual key/value pairs within well known configuration files without resorting to tools like
sed or
perl and
regular expressions. With augeas each key/value pair is assigned a path and can be queried and updated using that path. It offers both API and CLI interfaces though it's not nearly as commonly used as it should be.
The down side of Augeas is that it doesn't include a description (
lens in Augeas terminology) for Pulp config files. Pulp is too new. The upside is that the Pulp config files are fairly standard INI format, and it's easy to adapt the stock
IniFile lens for Pulp.
I won't include the lens text inline here, but I
put it in a gist if you want to look at it.
The ADD directive on line 20 of the Dockerfile places the lens file in the Augeas library where it will be found automatically.
Pulp Server Configuration Script
All of the containers that use this base image will need to set a few configuration values for Pulp. These reside in
/etc/pulp/server.conf which is an INI formatted text file. These settings indicate the identity of the pulp service itself and how the pulp processes communicate with the database and message bus.
If you are starting a Docker container by hand you could either pass these values in as environment variables using the -e (--env) option or by accepting additional positional arguments through the CMD. You'd have to establish the MongoDB and QPID services then get their IP addresses from Docker and feed the values into the Pulp server containers.
Since Kubernetes is controlling the database and messaging pods and has the Service objects defined, it knows how to tell the Pulp containers where to find these services. It sets a few environment variables for every new container that starts after the service object is created. A new container can use these values to reach the external services it needs.
Line 23 of the Dockerfile adds a short shell script which can accept the values from the environment variables that Kubernetes provides and configure them into the Pulp configuration.
The script gathers the set of values it needs from the variables (or sets reasonable defaults) and then, using augtool (The CLI tool for Augeas) it updates the values in the
pulp.conf file.
This is the snippet from the beginning of the
configure_pulp_server.sh script which sets the environment variables.
# Take settings from Kubernetes service environment unless they are explicitly
# provided
PULP_SERVER_CONF=${PULP_SERVER_CONF:=/etc/pulp/server.conf}
export PULP_SERVER_CONF
PULP_SERVER_NAME=${PULP_SERVER_NAME:=pulp.example.com}
export PULP_SERVER_NAME
SERVICE_HOST=${SERVICE_HOST:=127.0.0.1}
export SERVICE_HOST
DB_SERVICE_HOST=${DB_SERVICE_HOST:=${SERVICE_HOST}}
DB_SERVICE_PORT=${DB_SERVICE_PORT:=27017}
export DB_SERVICE_HOST DB_SERVICE_PORT
MSG_SERVICE_HOST=${MSG_SERVICE_HOST:=${SERVICE_HOST}}
MSG_SERVICE_PORT=${MSG_SERVICE_PORT:=5672}
MSG_SERVICE_USER=${MSG_SERVICE_USER:=guest}
export MSG_SERVICE_HOST MSG_SERVICE_PORT MSG_SERVICE_NAME
These are the values that the rest of the script will set into /etc/pulp/server.conf
UPDATE: As of the middle of October 2014 the SERVICE_HOST variable has been removed. Now each service gets its own IP address, so the generic SERVICE_HOST variable no longer makes sense. Each service variable must be provided explicitly when testing. Also, for testing the master host will provide a proxy to the service. However, as of this update the mechanism isn't working yet. I'll update this post when is working properly. If you are building from git source you can use a commit prior to 10/14/2014 and you can still use SERVICE_HOST test against the minions.
Container Startup and Remote Service Availability
When the Pulp service starts up it will attempt to connect to a MongoDB and to a QPID message broker. If the database isn't ready, the Pulp service may just hang.
Using Kubernetes it's best not to assume that the containers will arrive in any particular order. If the database service is unavailable, the pulp containers should just die. Kubernetes will notice and attempt to restart them periodically. When the database service is available the next client container will connect successfully and... not. die.
I have added a check script to the base container which can be used to test the availability (and the correct access information) for the MongoDB. It also uses the environment variables provided by Kubernetes when the container starts.
This script merely returns a shell true (return value: 0) if the database is available and false (return value: 1) if it fails to connect. This allows the startup script for the actual pulp service containers to check before attempting to start the pulp process and to cleanly report an error if the database is unavailable before exiting.
I haven't included a script to test the QPID connectivity. So far I haven't seen a pulp service fail to start because the QPID service was unavailable when the client container starts.
Scripts are not executed in the base image
The scripts listed above are provided in the base image, but the the base image has no ENTRYPOINT or CMD directives. It is not meant to be run on its own.
Each of the Pulp service images that uses this base will need to have a run script which will call these common scripts to set up the container environment before invoking the Pulp service processes. That's next.
Using a Base Image: The Pulp-Beat Component
The Pulp service is based on Celery. Celery is a framework for creating distributed task-based services. You extend the Celery framework to add the specific tasks that your application needs.
The task management is controlled by a "beat" process. Each Celery based service has to have exactly one beat server which is derived from the Celery scheduler class.
The beat server is a convenient place to do some of the service setup. Since there can only be one beat server and because it must be created first, I can use the beat service container startup to initialize the database.
The Docker development best-practices encourage image composition by layering. Creating a new layer means creating a new build space with a Dockerfile and any files that will be pulled in when the image is built.
In the case of the pulp-base image all of the content is there. The customizations for the pulp-beat service are just the run script which configures and initializes the the service before starting. The Dockerfile is trivially simple:
The real meat is in the run script, though even that is pretty anemic
The main section starts at line 44 and it's really just four steps. Two are defined in the base image scripts and two more are defined here.
- Apply the configuration customizations from the environment
These include setting the PULP_SERVER_NAME and the access parameters for the MongoDB and QPID services
- Verify that the MongoDB is up and accessable
With Kubernetes you can't be dependent on ordering of the pod startups. This check allows some time for the DB to start and become available. Kubernetes will restart the beat pod if this fails but the checks here prevent some thrashing.
- Initialize the MongoDB
This should only happen once. Within a pulp service the beat server is a singleton. I put the initialization step here so that it won't be confused later.
- Execute the master process
This is a celery beat process customized with the Pulp master object
Even though the script line for each operation is fairly trivial I still put them into their own functions. This makes it easier for a reader to understand the logical progression and intent before going back to the function and examining the details. It also makes it easier to comment out a single function for testing and debugging.
Testing the Beat Image (stand-alone)
Since Kubernetes currently gives so little real access debug information for the container startup process I'm going to test the Pulp beat container first as a regular Docker container. I have my Kubernetes cluster running in Vagrant and I know the IP addresses of the MongoDB and QPID services.
The other reason to test in plain Docker is that I want to manually verify the code which picks up and uses the configuration environment variables. There are four variables that will be required and two others that will likely default.
- PULP_SERVER_NAME
- SERVICE_HOST
- DB_SERVICE_HOST
- MSG_SERVICE_HOST
The defaulted ones will be
- DB_SERVICE_PORT
- MSG_SERVICE_PORT
DB_SERVICE_HOST and MSG_SERVICE_HOST can be provided directly or can pick up the value of SERVICE_HOST. I want to test both paths.
To test this I'm going to be running the Kubernetes Vagrant cluster on Virtualbox to provide the MongoDB and QPID servers. Then I'll run the Pulp beat server in Docker on the host. I know how to tell the beat server how to reach the services in the Kubernetes cluster (on 10.245.2.{2-4]}).
I'm going to assume that both the pulp-base and pulp-beat images are already built. I'm also going to start the container the first time using /bin/sh so I can manually start the run script and observe what it does.
docker run -d --name pulp-beat -v /dev/log:/dev/log \
> -e PULP_SERVER_NAME=pulp.example.com \
> -e SERVICE_HOST=10.245.2.2 markllama/pulp-beat
f16a6f2278e20e0b039cb665bc5f55de39b13a1045f00e25cdab5219652f1d80
This starts the container as a daemon and mounts /dev/log so that syslog will work. It also sets the PULP_SERVER_NAME and SERVICE_HOST variables.
docker logs pulp-beat
+ '[' '!' -x /configure_pulp_server.sh ']'
+ . /configure_pulp_server.sh
++ set -x
++ PULP_SERVER_CONF=/etc/pulp/server.conf
++ export PULP_SERVER_CONF
++ PULP_SERVER_NAME=pulp.example.com
++ export PULP_SERVER_NAME
++ SERVICE_HOST=10.245.2.2
++ export SERVICE_HOST
++ DB_SERVICE_HOST=10.245.2.2
++ DB_SERVICE_PORT=27017
++ export DB_SERVICE_HOST DB_SERVICE_PORT
++ MSG_SERVICE_HOST=10.245.2.2
++ MSG_SERVICE_PORT=5672
++ MSG_SERVICE_USER=guest
++ export MSG_SERVICE_HOST MSG_SERVICE_PORT MSG_SERVICE_NAME
++ check_config_target
++ '[' '!' -f /etc/pulp/server.conf ']'
++ configure_server_name
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''server'\'']/server_name' pulp.example.com
Saved 1 file(s)
++ configure_database
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''database'\'']/seeds' 10.245.2.2:27017
Saved 1 file(s)
++ configure_messaging
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''messaging'\'']/url' tcp://10.245.2.2:5672
Saved 1 file(s)
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''tasks'\'']/broker_url' qpid://guest@10.245.2.2:5672
Saved 1 file(s)
+ '[' '!' -x /test_db_available.py ']'
+ wait_for_database
+ DB_TEST_TRIES=12
+ DB_TEST_POLLRATE=5
+ TRY=0
+ '[' 0 -lt 12 ']'
+ /test_db_available.py
Testing connection to MongoDB on 10.245.2.2, 27017
+ '[' 0 -ge 12 ']'
+ initialize_database
+ runuser apache -s /bin/bash /bin/bash -c /usr/bin/pulp-manage-db
Loading content types.
Content types loaded.
Ensuring the admin role and user are in place.
Admin role and user are in place.
Beginning database migrations.
Applying pulp.server.db.migrations version 1
Migration to pulp.server.db.migrations version 1 complete.
...
Applying pulp_rpm.plugins.migrations version 16
Migration to pulp_rpm.plugins.migrations version 16 complete.
Database migrations complete.
+ run_celerybeat
+ exec runuser apache -s /bin/bash -c '/usr/bin/celery beat --workdir=/var/lib/pulp/celery --scheduler=pulp.server.async.scheduler.Scheduler -f /var/log/pulp/celerybeat.log -l INFO'
This shows why I set the -x at the beginning of the run script. It causes the shell to emit each line as it is executed. You can see the environment variables as they are set. Then they are used to configure the pulp server.conf values. The database is checked and then initialized. Finally it executes the celery beat process which replaces the shell and continues executing.
When this script runs it should have several side effects that I can check. As noted, it creates and initializes the pulp database. It also connects to the QPID server and creates several queues. I can check them in the same way I did when I created the MongoDB and QPID images in the first place.
The database has been initialized
echo show dbs | mongo 10.245.2.2
MongoDB shell version: 2.4.6
connecting to: 10.245.2.2/test
local 0.03125GB
pulp_database 0.03125GB
bye
And the celery beat service has added a few queues to the QPID service
qpid-config queues -b guest@10.245.2.4
Queue Name Attributes
======================================================================
0b78268e-256f-4832-bbcc-50c7777a8908:1.0 auto-del excl
411cc98f-eed3-45f9-b455-8d2e5d333262:0.0 auto-del excl
aaf61614-919e-49ea-843f-d83420e9232f:1.0 auto-del excl
celeryev.de500902-4c88-4d5c-90f4-1b4db366613d auto-del --limit-policy=ring --argument passive=False --argument exclusive=False --argument arguments={}
But what if I do it wrong?
You can see that the output from a correct startup is pretty lengthy. When I'm happy that the image is stable I'll remove the shell -x setting (and make it either an argument or environment switch for later). There are several other paths to test.
- Fail to provide Environment Variables
- PULP_SERVER_NAME
- SERVICE_HOST
- DB_SERVICE_HOST
- MSG_SERVICE_HOST
- Fail to import /dev/log volume
Each of these will have slightly different failure modes. I suggest you try each of them and observe how it fails. Think of others, I'm sure I've missed some.
For the purposes of this post I'm going to treat these as exercises for the reader and move on.
Testing the Beat Image (Kubernetes)
Now things get interesting. I have to craft a Kubernetes pod description that creates the pulp-beat container, gives it access to logging and connects it to the database and messaging services.
Defining the Pulp Beat pod
Because of the way I crafted the base image and run scripts, this isn't actually as difficult or as complicated as you might think. It turns out that the only environment variable I have to actually pass in is the PULP_SERVER_NAME. The rest of the environment values are going to be provided by the kubelet as defined by the Kubernetes service objects (and served by the MongoDB and QPID containers behind them).
The only really significant thing here is the volume imports.
Pulp uses the python logging mechanism and that in turn by default requires the
syslog service. On Fedora 20, syslog is no longer a separate process. It's been absorbed into the systemd suite of low level services and is known now as
journald. (cat flamewars/systemd/{pro,con} >/dev/null).
For me this means that for Pulp to run properly it needs the ability to write syslog messages. In Fedora 20 this amounts to being able to write to a special file
/dev/log. This file isn't available in containers without some special magic. For Docker that magic is
-v /dev/log:/dev/log. This imports the host's
/dev/log into the container at the same location. For Kubernetes this is a little bit more involved.
The Kubernetes pod construct has some interesting side-effects. The purpose of pods is to allow the creation of sets of containers that share resources. The JSON reflects this in how the shared resources are declared.
In the pod spec,
lines 14-20 are inside the container hash for the container named
pulp-beat. They indicate that a volume named "devlog" (line 15) will be mounted read/write (line 16) on
/dev/log inside the container (line 17).
Note that this section does not define the named volume or indicate where it will come from. That's defined at the pod level not the container.
Now look at
lines 20-23. these are at the pod level (the list of containers has been closed on line 19). The
volumes array contains a set of volume definitions. I only define one, named "devlog" (line 21) and indicate that it comes from the host and that the source path is
/dev/log.
All that to replace the docker argument -v /dev/log:/dev/log.
Right now this seems like a lot of work for a trivial action. Later this distinction will become very important. The final pod for Pulp will be made up of at least two containers. The pod will import two different storage locations from the host and both containers will mount them.
One last time for clarity: the
volumes list is at the pod level. It defines a set of external resources that will be made available to the containers in the pod. The volumeMounts list is at the container level. It maps entries from the volumes section in the pod to mount points inside the container using the value of the name as the connecting handle.
Starting the Pulp Beat Pod
Starting the pulp beat pod is just like starting the MongoDB and QPID pods was. At this point it does require that the Service objects have been created and that the service containers are running, so if you're following along and haven't done that, go do it. Since I'd run my pulp beat container manually and it had modified the mongodb, I also removed the pulp_database before proceeding.
echo 'db.dropDatabase()' | mongo 10.245.2.2/pulp_database
MongoDB shell version: 2.4.6
connecting to: 10.245.2.2/pulp_database
{ "dropped" : "pulp_database", "ok" : 1 }
bye
echo show dbs | mongo 10.245.2.2
MongoDB shell version: 2.4.6
connecting to: 10.245.2.2/test
local 0.03125GB
bye
To start the pulp beat pod we go back to kubecfg (remember, I aliased
kubecfg=~/kubernetes/cluster/kubecfg.sh).
kubecfg -c pods/pulp-beat.json create pods
ID Image(s) Host Labels Status
---------- ---------- ---------- ---------- ----------
pulp-beat markllama/pulp-beat / name=pulp-beat Waiting
kubecfg get pods/pulp-beat
ID Image(s) Host Labels Status
---------- ---------- ---------- ---------- ----------
pulp-beat markllama/pulp-beat 10.245.2.2/10.245.2.2 name=pulp-beat Waiting
Now I know that the pod has been assigned to 10.245.2.2 (minion-1) I can log in there directly and examine the docker container.
vagrant ssh minion-1
Last login: Fri Dec 20 18:02:34 2013 from 10.0.2.2
sudo docker ps | grep pulp-beat
2515129f2c7e markllama/pulp-beat:latest "/run.sh" 54 seconds ago Up 53 seconds k8s--pulp_-_beat.a6ba93e9--pulp_-_beat.etcd--d2a60369_-_458d_-_11e4_-_b682_-_0800279696e1--0b799f3d
sudo docker logs 2515129f2c7e
+ '[' '!' -x /configure_pulp_server.sh ']'
+ . /configure_pulp_server.sh
++ set -x
++ PULP_SERVER_CONF=/etc/pulp/server.conf
++ export PULP_SERVER_CONF
++ PULP_SERVER_NAME=pulp.example.com
++ export PULP_SERVER_NAME
++ SERVICE_HOST=10.245.2.2
++ export SERVICE_HOST
++ DB_SERVICE_HOST=10.245.2.2
++ DB_SERVICE_PORT=27017
++ export DB_SERVICE_HOST DB_SERVICE_PORT
++ MSG_SERVICE_HOST=10.245.2.2
++ MSG_SERVICE_PORT=5672
++ MSG_SERVICE_USER=guest
++ export MSG_SERVICE_HOST MSG_SERVICE_PORT MSG_SERVICE_NAME
++ check_config_target
++ '[' '!' -f /etc/pulp/server.conf ']'
++ configure_server_name
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''server'\'']/server_name' pulp.example.com
Saved 1 file(s)
++ configure_database
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''database'\'']/seeds' 10.245.2.2:27017
Saved 1 file(s)
++ configure_messaging
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''messaging'\'']/url' tcp://10.245.2.2:5672
Saved 1 file(s)
++ augtool -s set '/files/etc/pulp/server.conf/target[. = '\''tasks'\'']/broker_url' qpid://guest@10.245.2.2:5672
Saved 1 file(s)
+ '[' '!' -x /test_db_available.py ']'
+ wait_for_database
+ DB_TEST_TRIES=12
+ DB_TEST_POLLRATE=5
+ TRY=0
+ '[' 0 -lt 12 ']'
+ /test_db_available.py
Testing connection to MongoDB on 10.245.2.2, 27017
+ '[' 0 -ge 12 ']'
+ initialize_database
+ runuser apache -s /bin/bash /bin/bash -c /usr/bin/pulp-manage-db
Loading content types.
Content types loaded.
Ensuring the admin role and user are in place.
Admin role and user are in place.
Beginning database migrations.
Applying pulp.server.db.migrations version 1
Migration to pulp.server.db.migrations version 1 complete.
...
Applying pulp_rpm.plugins.migrations version 16
Migration to pulp_rpm.plugins.migrations version 16 complete.
Database migrations complete.
+ run_celerybeat
+ exec runuser apache -s /bin/bash -c '/usr/bin/celery beat --workdir=/var/lib/pulp/celery --scheduler=pulp.server.async.scheduler.Scheduler -f /var/log/pulp/celerybeat.log -l INFO'
If this is the first time running the image it may take a while for Kubernetes/Docker to pull it from the Docker hub. There may be a delay as the kubernetes pause container does the pull.
I can now run the same tests I did earlier on the MongoDB and QPID services to reassure myself that the pulp beat service is connected.
echo show dbs | mongo 10.245.2.2
MongoDB shell version: 2.4.6
connecting to: 10.245.2.2/test
local 0.03125GB
pulp_database 0.03125GB
bye
qpid-config queues -b guest@10.245.2.4
Queue Name Attributes
======================================================================
613f4b89-e63e-4230-9620-e932f5a777e5:0.0 auto-del excl
c990ea7b-3d7f-4603-80e5-176ebc649ff1:1.0 auto-del excl
celeryev.ffbc537b-1161-4049-b425-723487135fc2 auto-del --limit-policy=ring --argument passive=False --argument exclusive=False --argument arguments={}
e0155372-12ee-4c9a-9c4d-8f4863601b3a:1.0 auto-del excl
After all that thought and planning the end result is actually kinda boring. Just the way I like it.
What's next?
The pulp-beat service is just the first real pulp component. It runs in isolation from the other components, communicating only through the messaging and database. There is another component like that, the
pulp-resource-manager. This is another Celery process and the it is created, started and tested just like the pulp-beat service. I'm going to do one much-shorter post on that for completeness before tackling the next level of complexity.
The two remaining different components are the content pods, which require shared storage and which will have two cooperating containers running inside the pod. One will manage the content mirroring and the other will serve the content out to clients.
I think before that though I will tackle the Pulp Admin service. This is a public facing REST service which accepts pulp admin commands to create and manage the content repositories.
Both of these will require the establishment of encryption, which means placing x509 certificates within the containers. These are the upcoming challenges.
References
- Docker - Containerized applications
- Kubernetes - Orchestration for creating containerized services
- MongoDB - A Non-relational database
- QPID - an AMQP messaging service
- Pulp - An enterprise OS content mirroring system
- Celery - A Distributed Task Queue Framework
- Augeas - Structured queries and updates to (largely) unstructured configurations
- INI Files - A simple format for simple configurations


.png)
.png)