This is the second of three posts on storage management in
Docker:
This is a side trip on my way to creating a containerized
Pulp content mirroring service using
Docker and
Kuberentes. The storage portion is important (and confusing) enough to warrant special attention.
Persistent Storage
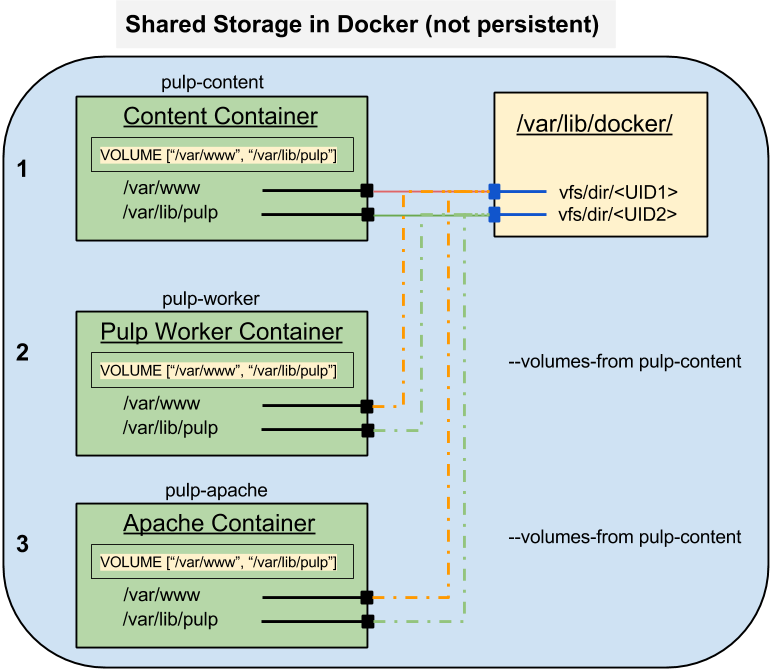
In the previous post I talked about the mechanisms that Docker offers for sharing storage between containers. This kind of storage is limited to containers on the same host and it does not survive after the last connected container is destroyed.
If you're running a long-lived service like a database or a file repository you're going to need storage which exists outside the container space and has a life span longer than the container which uses it.
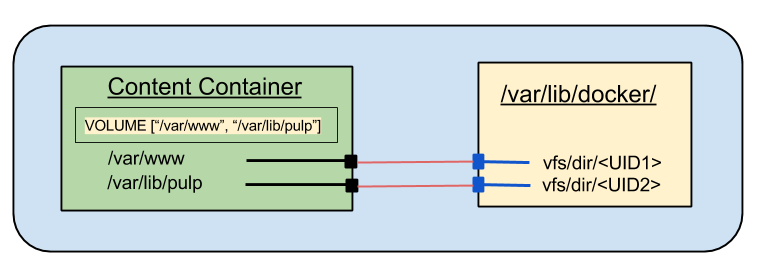
The Dockerfile VOLUME directive is the mechanism to define where external storage will be mounted inside a container.
NOTE: I'm only discussing single host local storage. The issues around network storage are still wide open and beyond the scope of a single post.
Container Views and Context
Containers work by providing two different views of the resources on the host. Outside the container, the OS can see everything, but the processes inside are fooled into seeing only what the container writer wants them to see. The problem is not just what they see though, but how they see it.
There are a number of resources which define the view of the OS. The most significant ones for file storage are the user and group databases (in /etc/passwd and /etc/group). The OS uses numeric UID and GID values to identify users and decide how to apply permissions. These numeric values are mapped to names using the passwd and group files. The host and containers each have their own copies of these files and the entries in these files will almost certainly differ between the host and the container. The ownership and permissions on the external file tree must be set to match the expectations of the processes which will run in the container.
SELinux also controls access to file resources. The SELinux labels on the file tree on the host must be set so that system policy will allow the processes inside the container to operate on them as needed.
In this post most of my effort will be spent looking at the view from inside and adjusting the settings on the file tree outside to allow the container processes to do their work.
Dockerfile VOLUME directive Redux
As noted in the previous post, the VOLUME directive defines a boundary in the filesystem within a container. That boundary can be used as a handle to export a portion of the container file tree. It can also be used to mark a place to mount an external filesystem for import to the container.
When used with the Docker CLI --volumes-from option it is possible to create containers that share storage from one container to any number of others. The mount points defined in the VOLUME directives are mapped one-to-one from the source container to the destinations.
Importing Storage: The --volume CLI option
When starting a Docker container I can cause Docker to map any external path to an internal path using the --volume (or -v) option. This option takes two paths separated by a colon (:). The first path is the host file or directory to be imported into the container. The second is the mount point within the container.
docker run --volume <host path>:<container path> ...
Example: MongoDB persistent data
Say I want to run a database on my host, but I don't want to have to install the DB software into the system. Docker makes it possible for me to run my database in a container and not have to worry about which version the OS has installed. However, I do want the data to persist if I shut the container down and restart it, whether for maintenance or to upgrade the container.
The Dockerfile for my MongoDB container looks like this:
- Lines 1 and 2 are the boilerplate you've seen to define the base image and the maintainer information.
- Line 7 installs the MongoDB server package
- Lines 9 - 11 create the directory for the database storage and ensures that it will not be pruned by placing a hidden file named .keep inside. They also set the permissions for that directory in the context of the container view to allow the mongodb user to write the directory.
- Line 15 specifies the location of the imported volume.
- Line 17 opens the firewall for inbound connections to the MongoDB
- Lines 19 and 20 set the user that will run the primary process and the location where it will start.
- Lines 22 and 23 define the binary to execute when the container starts and the default arguments
To run a shell in the container, use the
--entrypoint option. Arguments to the docker run command will be passed directly to the mongod process, overriding the defaults.
What works?
I know that this image works when I just use the default internal Docker storage. I know that file ownership and permissions will be an issue, so the first thing to do is to look inside a working container and see what the ownership and permissions look like.
docker run -it --name mongodb --entrypoint /bin/sh markllama/mongodb
sh-4.2$ id
uid=184(mongodb) gid=998(mongodb) groups=998(mongodb)
sh-4.2$ ls -ldZ /var/lib/mongodb
drwxr-xr-x. mongodb mongodb system_u:object_r:docker_var_lib_t:s0 /var/lib/mongodb
Now I know the UID and GID which the container process uses (UID = 184, GID = 998). I'll have to make sure that this user/group can write to the host directory which I map into the container.
I know that the default permissions are 755 (rwx, r-x, r-x), which is fairly common.
I also see that the directory has a special SELinux label:
docker_var_lib_t.
Together, the directory ownership/permissions and the SELinux policy could prevent access by the container process to the host files. Both are going to require root access on the host to fix.
Interesting Note: When inside the container, attempts to determine the process SELinux context are met with a message indicating that SELinux is not enabled. Apparently, from the view point inside the container, it isn't.
Preparing the Host Directory
I could just go ahead and create a directory with the right ownership, permissions and label and attach it to my MongoDB container and say "Voila!". What fun would that be? Instead I'm going to create the target directory and mount it into a container and try writing to it from inside. When that fails I'll update the ownership, permissionad and label, (from outside) each time checking the view and capabilities (from inside) to see how it changes.
I am going to disable SELinux temporarily so I can isolate the file ownership/permissions from the SELinux labeling.
sudo setenforce 0
mkdir ~/mongodb
ls -ldZ ~/mongodb
drwxrwxr-x. mlamouri mlamouri unconfined_u:object_r:user_home_t:s0 /home/mlamouri/mongodb
I'm also going to create a file inside the directory (from the view of the host) so that I can verify (from the view in the container) that I've mounted the correct directory.
touch ~/mongodb/from_outside
ls -lZ ~/mongodb/from_outside
-rw-rw-r--. mlamouri mlamouri unconfined_u:object_r:user_home_t:s0 /home/mlamouri/mongodb/from_outside
Note the default ownership and permissions on that file.
Now I'm ready to try mounting that into the mongodb container (knowing that write access will fail)
Starting the Container with a Volume Mounted
I want to be able to examine the runtime environment inside the container before I let it fly with a mongod process. I'll set the entrypoint on the CLI to run a shell instead and use the -it options so it runs interactively and terminates when I exit the shell.
The external path to the volume is /home/mlamouri/mongodb and the internal path is /var/lib/mongodb.
docker run -it --name mongodb --volume ~/mongodb:/var/lib/mongodb --entrypoint /bin/sh markllama/mongodb
sh-4.2$ id
uid=184(mongodb) gid=998(mongodb) groups=998(mongodb)
sh-4.2$ pwd
/var/lib/mongodb
sh-4.2$ ls
from_outside
sh-4.2$ ls -ld /var/lib/mongodb
drwxrwxr-x. 2 15149 15149 4096 Oct 9 21:04 /var/lib/mongodb
sh-4.2$ touch from_inside
touch: cannot touch 'from_inside': Permission denied
As expected, From inside the container, I can't write the mounted volume. I can read it (with SELinux disabled) because I have te directory permissions open to the world for read and execute. Now I'll change the ownership of the directory from the outside.
Adjusting The Ownership
sudo chown 184:998 ~/mongodb
ls -ld ~/mongodb
drwxrwxr-x. 2 mongodb polkitd 4096 Oct 9 20:46 /home/bos/mlamouri/mongodb
It turns out I have the mongo-server package installed on my host and it has assigned the same UID to the monogodb user as the container has. However, the group for mongodb inside the container corresponds to the polkitd group on the host.
Now I can try writing a file there from the inside again. From the (still running) container shell:
sh-4.2$ ls -l
total 0
-rw-rw-r--. 1 mongodb mongodb 0 Oct 9 20:46 from_outside
sh-4.2$ touch from_inside
sh-4.2$ ls -l
total 0
-rw-r--r--. 1 mongodb mongodb 0 Oct 10 01:55 from_inside
-rw-rw-r--. 1 mongodb mongodb 0 Oct 9 20:46 from_outside
sh-4.2$ ls -Z
-rw-r--r--. mongodb mongodb system_u:object_r:user_home_t:s0 from_inside
-rw-rw-r--. mongodb mongodb unconfined_u:object_r:user_home_t:s0 from_outside
Re-Enabling SELinux (and causing fails again)
There are two access control barriers for files. The Linux file ownership and permissions are one. The second is SELinux and I have to turn it back on. This will break things again until I also set the SELinux label on the directory on the host.
sudo setenforce 1
Now when I try to read the directory inside the container or create a file, the request is rejected with permission denied.
sh-4.2$ ls
ls: cannot open directory .: Permission denied
sh-4.2$ touch from_inside_with_selinux
touch: cannot touch 'from_inside_with_selinux': Permission denied
Just to refresh, here's the SELinux label for the directory as seen from the host:
ls -dZ mongodb
drwxrwxr-x. mongodb polkitd unconfined_u:object_r:user_home_t:s0 mongodb
SELinux Diversion: What's Happening?
In the end I'm just going to apply the SELinux label which I found on the volume directory when I used Docker internal storage. I'm going to step aside for a second here though and look at how I can find out more about what SELinux is rejecting
When SELinux rejects a request it logs that request. The logs go into
/var/log/audit/audit.log. These are definitely cryptic and can be daunting but they're not entirely inscrutable.
First I can use what I know to filter out things I don't care about. I know I want AVC messages (AVC is an abbreviation for Access Vector Cache. Yeah. Not useful). These messages are indicated by type=AVC in the logs. Second, I know that I am concerned with attempts to access files labeled user_home_t. These two will help me narrow down the messages I care about.
These are very long lines so you may have to scroll right a bit to see the important parts.
sudo grep type=AVC /var/log/audit/audit.log | grep user_home_t
type=AVC msg=audit(1412948687.224:8235): avc: denied { add_name } for pid=11135 comm="touch" name="from_inside" scontext=system_u:system_r:svirt_lxc_net_t:s0:c687,c763 tcontext=unconfined_u:object_r:user_home_t:s0 tclass=dir permissive=1
type=AVC msg=audit(1412948687.224:8235): avc: denied { create } for pid=11135 comm="touch" name="from_inside" scontext=system_u:system_r:svirt_lxc_net_t:s0:c687,c763 tcontext=system_u:object_r:user_home_t:s0 tclass=file permissive=1
type=AVC msg=audit(1412948876.731:8257): avc: denied { write } for pid=12800 comm="touch" name="mongodb" dev="sda4" ino=7749584 scontext=system_u:system_r:svirt_lxc_net_t:s0:c687,c763 tcontext=unconfined_u:object_r:user_home_t:s0 tclass=dir permissive=0
type=AVC msg=audit(1412948898.965:8258): avc: denied { write } for pid=11108 comm="sh" name=".bash_history" dev="sda4" ino=7751785 scontext=system_u:system_r:svirt_lxc_net_t:s0:c687,c763 tcontext=system_u:object_r:user_home_t:s0 tclass=file permissive=0
type=AVC msg=audit(1412948898.965:8259): avc: denied { append } for pid=11108 comm="sh" name=".bash_history" dev="sda4" ino=7751785 scontext=system_u:system_r:svirt_lxc_net_t:s0:c687,c763 tcontext=system_u:object_r:user_home_t:s0 tclass=file permissive=0
type=AVC msg=audit(1412948898.965:8260): avc: denied { read } for pid=11108 comm="sh" name=".bash_history" dev="sda4" ino=7751785 scontext=system_u:system_r:svirt_lxc_net_t:s0:c687,c763 tcontext=system_u:object_r:user_home_t:s0 tclass=file permissive=0
type=AVC msg=audit(1412949007.595:8289): avc: denied { read } for pid=14158 comm="sh" name=".bash_history" dev="sda4" ino=7751785 scontext=system_u:system_r:svirt_lxc_net_t:s0:c184,c197 tcontext=system_u:object_r:user_home_t:s0 tclass=file permissive=0
type=AVC msg=audit(1412949674.712:8307): avc: denied { write } for pid=14369 comm="touch" name="mongodb" dev="sda4" ino=7749584 scontext=system_u:system_r:svirt_lxc_net_t:s0:c184,c197 tcontext=unconfined_u:object_r:user_home_t:s0 tclass=dir permissive=0
I found something I hadn't really expected. Every time I try to type a command in the shell within the container, the shell tries to write to the
.bash_history file. This Is only an issue when I'm testing the container with a shell. Remember in the Dockerfile I set the WORKDIR directive to the top of the MongoDB data directory. That means when I start the shell in the container, the current working directory is /var/log/mongodb. Which is the directory I'm trying to import. This won't matter when I'm running the daemon properly as there won't be any shell.
The important thing this shows me is the SELinux context of the shell process within the container: system_u:system_r:svirt_lxc_net_t:s0 . (note that I dropped off the MVC context, the "cc87,c763" on the end). That is the process which is being denied access to the working directory.
Given that list of AVCs I can feed them to audit2allow and get a big-hammer policy change to stop the AVCs.
sudo grep type=AVC /var/log/audit/audit.log | grep user_home_t| audit2allow
#============= svirt_lxc_net_t ==============
allow svirt_lxc_net_t user_home_t:dir { write remove_name add_name };
allow svirt_lxc_net_t user_home_t:file { write read create unlink open append };
This is a nice summary of what is happening and what fails. You could use this output to create a policy module which would allow this activity. DON'T DO IT. It's tempting to use audit2allow to just open things up when SELinux prevents things. Without understanding what your changing and why you risk creating holes you didn't mean to.
Instead I'm going to proceed by assigning a label to the directory tree which indicates what I mean to use it for (content for Docker containers). That is, by labeling the directory to allow Docker to mount and write it, it becomes evident to someone looking at it later what I meant to do.
Labeling the MongoDB directory for use by Docker
The processes running within Docker appear to have the SELinux context system_u:system_r:svirt_lxc_net_t. From the example using the Docker internal storage for /var/lib/mongodb I know that the directory is labled system_u:object_r:docker_var_lib_t:s0. If I apply that label to my working directory, the processes inside the container should be able to write to the directory and its children.
The SELinux tool for updating object (file) labels is chcon (for change context). It works much like chown or chmod. Because I'm changing security labels that I don't own, I need to use sudo to make the change.
sudo chcon -R system_u:object_r:docker_var_lib_t:s0 ~/mongodb
ls -dZ mongodb/
drwxrwxr-x. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 mongodb/
ls -Z mongodb/
-rw-r--r--. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 from_inside
-rw-rw-r--. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 from_outside
getenforce
Enforcing
Now the directory and all its contents have the correct ownership, permissions and SElinux label. SELinux is enforcing. I can try writing from inside the container again.
sh-4.2$ touch from_inside_with_selinux
sh-4.2$ ls -l
total 0
-rw-r--r--. 1 mongodb mongodb 0 Oct 10 13:44 from_inside
-rw-r--r--. 1 mongodb mongodb 0 Oct 10 15:54 from_inside_with_selinux
-rw-rw-r--. 1 mongodb mongodb 0 Oct 9 20:46 from_outside
That's it. Time to try running mongod inside the container.
Running the Mongodb Container
First I shut down and remove my existing mongod container. Then I can start one up for real. I Switch from interactive (-it) to daemon (-d) mode and remove the --entrypoint argument.
sh-4.2$ exit
exit
docker rm mongodb
mongodb
docker run -d --name mongodb --volume ~/mongodb:/var/lib/mongodb markllama/mongodb
9e203806b4f07962202da7e0b870cd567883297748d9fe149948061ff0fa83f0
I should now have a running mongodb container
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9e203806b4f0 markllama/mongodb:latest "/usr/bin/mongod --c 34 seconds ago Up 33 seconds 27017/tcp mongodb
I can check the container logs to see if the process is running and indicates a good startup.
docker logs mongodb
note: noprealloc may hurt performance in many applications
Fri Oct 10 16:01:25.560 [initandlisten] MongoDB starting : pid=1 port=27017 dbpath=/var/lib/mongodb 64-bit host=9e203806b4f0
Fri Oct 10 16:01:25.562 [initandlisten]
Fri Oct 10 16:01:25.562 [initandlisten] ** WARNING: You are running on a NUMA machine.
Fri Oct 10 16:01:25.562 [initandlisten] ** We suggest launching mongod like this to avoid performance problems:
Fri Oct 10 16:01:25.562 [initandlisten] ** numactl --interleave=all mongod [other options]
Fri Oct 10 16:01:25.562 [initandlisten]
Fri Oct 10 16:01:25.562 [initandlisten] db version v2.4.6
Fri Oct 10 16:01:25.562 [initandlisten] git version: nogitversion
Fri Oct 10 16:01:25.562 [initandlisten] build info: Linux buildvm-12.phx2.fedoraproject.org 3.10.9-200.fc19.x86_64 #1 SMP Wed Aug 21 19:27:58 UTC 2013 x86_64 BOOST_LIB_VERSION=1_54
Fri Oct 10 16:01:25.563 [initandlisten] allocator: tcmalloc
Fri Oct 10 16:01:25.563 [initandlisten] options: { config: "/etc/mongodb.conf", dbpath: "/var/lib/mongodb", nohttpinterface: "true", noprealloc: "true", quiet: true, smallfiles: "true" }
Fri Oct 10 16:01:25.636 [initandlisten] journal dir=/var/lib/mongodb/journal
Fri Oct 10 16:01:25.636 [initandlisten] recover : no journal files present, no recovery needed
Fri Oct 10 16:01:27.469 [initandlisten] preallocateIsFaster=true 27.58
Fri Oct 10 16:01:29.329 [initandlisten] preallocateIsFaster=true 28.04
It looks like the daemon is running.
I can use
docker inspect to find the assigned IP address for the container. With that I can connect the mongo client to the service and test database access.
docker inspect --format '{{.NetworkSettings.IPAddress}}' mongodb
172.17.0.110
echo show dbs | mongo 172.17.0.110
MongoDB shell version: 2.4.6
connecting to: 172.17.0.110/test
local 0.03125GB
bye
I know the database is running and answering queries. The last check is to look inside the directory I created for the database. It should have the test files I'd created as well as the database and journal files which mongod will create on startup.
ls -lZ ~mongodb
-rw-r--r--. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 from_inside
-rw-r--r--. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 from_inside_with_selinux
-rw-rw-r--. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 from_outside
drwxr-xr-x. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 journal
-rw-------. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 local.0
-rw-------. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 local.ns
-rwxr-xr-x. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 mongod.lock
drwxr-xr-x. mongodb polkitd system_u:object_r:docker_var_lib_t:s0 _tmp
There they are.
Summary
It took a little work to get a Docker container running a system service using persistent host storage for the database files.
I had to get the container running without extra storage first and examine the container to see what it expected. The file ownership, permissions and the SELinux context all affect the ability to write files.
Tweaking for Storage
On the host I had to create a directory with the right characteristics. The UID and GID on the host may not match those inside the container. If the container service creates a user and group they will almost certainly not exist on a generic Docker container host.
The Docker service uses a special set of SELinux contexts and labels to run. Docker runs as root and it does lots of potentially dangerous things. The SELinux policies for Docker are designed to prevent contained processes from escaping, at least through the resources SELinux can control.
Setting the directory ownership and the SELinux context require root access. This isn't a really big deal as Docker also requires root (or at least membership in the docker group) but its another wart. It does mean that the ideal of running service containers in user space is an illusion. Once the directory is set up and running it will require root access to remove it as well. It's probably best not to place it in a user home directory as I did.
Scaling up: Multiple Hosts and Network Storage?
It is possible to run Docker service containers with persistent external storage from the host. This won't scale up to multiple hosts. Kubernetes has no way of making the required changes to the host. It might be possible to use network filesystems like NFS, Gluster or Ceph so long as the user accounts are made consistent.
The other possibility for shared storage is cloud storage. I'll talk about that some in the next post, though it's not ready for Docker and Kubernetes yet.
Pending Features: User Namespaces (SELinux Namespaces?)
The user mapping may be resolved by a pending feature addition to Linux namespaces and Docker: User namespaces. This would allow a UID inside a container to be mapped to a different UID on the host. The same would be true for GIDs. This would allow me to run a container which uses the mongodb UID inside the container but is able to access files owned by my UID on the host. I don't have a timeline for this feature and the developers still raise their eyebrows in alarm when I ask about it, but it is work in progress.
A feature which does not exist to my knowledge is SELinux namespaces. This is the idea that an SELinux label inside a container might be mapped to a different label outside. This would allow the docker_var_lib_dir_t label inside to be mapped to user_home_t outside. I suspect this would break lots of things and open up nasty holes so I don't expect it soon.
Next Up: Network (Cloud) Storage
Next up is some discussion (but not any demonstration at all) of the state of network storage
References


.png)
.png)